In this post I will show you how to send Kubernetes logs to multiple outputs by using Fluentd but first, let’s do a recap.
On the previous post I wrote about using Fluentd and FluentBit; in particular, I showed you how to use FluentBit for log collecting and forwarding and Fluentd for pushing these logs to a destination: Opensearch. Since Opensearch at the time didn’t have a Fluentd plugin, we had to craft our Dockerfile tailored for our use case by installing Ruby Gems and by specifing the latest Elasticsearch gem compatible with Opensearch.
FROM fluent/Fluentd:v1.13-debian-1
# Use root account to use apt
USER root
# below RUN includes plugin as examples elasticsearch is not required
# you may customize including plugins as you wish
RUN buildDeps="sudo make gcc g++ libc-dev" \
&& apt-get update \
&& apt-get install -y --no-install-recommends $buildDeps \
&& gem install elasticsearch-api -v 7.13.3 \
&& gem install elasticsearch-transport -v 7.13.3 \
&& gem install elasticsearch -v 7.13.3 \
&& gem install fluent-plugin-elasticsearch -v 5.1.0 \
&& sudo gem sources --clear-all \
&& SUDO_FORCE_REMOVE=yes \
apt-get purge -y --auto-remove \
-o APT::AutoRemove::RecommendsImportant=false \
$buildDeps \
&& rm -rf /var/lib/apt/lists/* \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
RUN mkdir -p /var/log/Fluentd-buffers/ && chown -R fluent /var/log/Fluentd-buffers/
USER fluent
At the time of writing you can swap the Gems above that are targeting Elasticsearch with Opensearch:
gem install fluent-plugin-opensearch
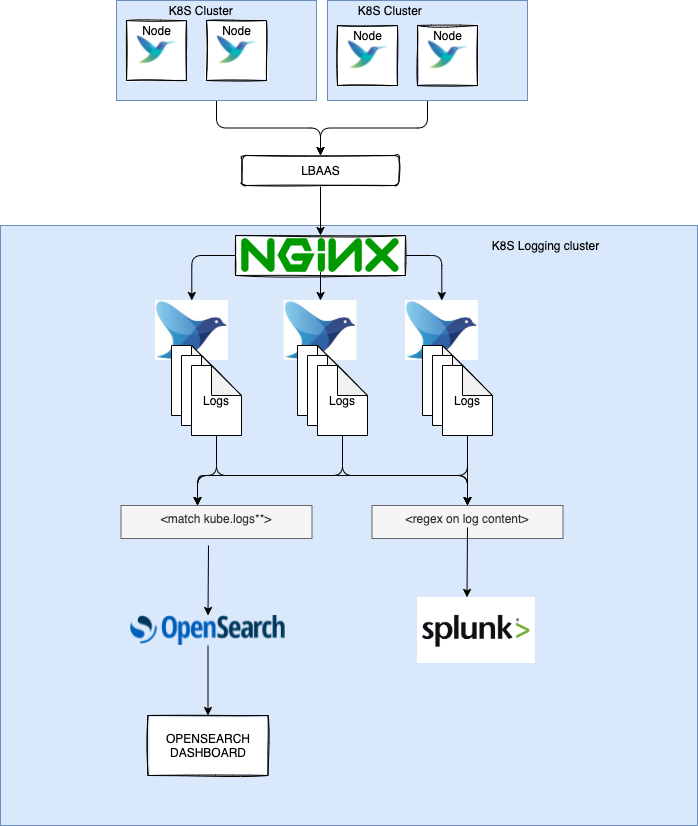
In the Fluentd configuration then we specified the output destination to be @type Opensearch . But what if we wanted to send our logs to multiple destination? Maybe collecting all the logs into Opensearch but sending specific logs (maybe by applying a regex on the pod name) to another destination such as Splunk?
Fluentd configuration
In order to send logs to multiple destination we can use the @type copy output plugin which copies events to multiple outputs.
---
# Source: Fluentd-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: Fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
all-logs.conf: |-
<match kube.logs**>
@type copy
<store>
@type opensearch
@id out_all_logs
@log_level "info"
id_key _hash
remove_keys _hash
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST'] || 'localhost'}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT'] || '9200'}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER'] || 'admin'}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD'] || 'admin'}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify false
reload_connections false
reconnect_on_error true
reload_on_failure true
logstash_prefix "all-logs"
logstash_dateformat "%Y.%m.%d"
logstash_format true
template_overwrite true
request_timeout 30s
<buffer>
@type file
path /var/log/Fluentd-buffers/myproject/kubernetes.system.buffer
retry_type exponential_backoff
flush_thread_count 2
flush_interval 10s
retry_max_interval 30
retry_forever true
chunk_limit_size 8M
queue_limit_length 512
overflow_action block
</buffer>
</store>
<store>
@type rewrite_tag_filter
<rule>
key log
pattern \[(RESPONSE|REQUEST)\]\s+:\s+Method\s+=>\s+(login|logout)\s+ClassName
tag splunk.myapp
</rule>
<rule>
key log
pattern User logged in|Huston, we have a problem|User logged out
tag splunk.myapp
</rule>
<rule>
key log
pattern ERROR|FATAL
tag splunk.myapp
</rule>
</store>
</match>
<match splunk.myapp**>
@type splunk_hec
hec_host splunk.myhost.justinpolidori.it
protocol https
hec_port 4444
hec_token <my-token>
insecure_ssl false
</match>
With the copy plugin we can get the same events to multiple output by enclosing the output plugins inside the store directive. In the example above, we’re sending logs to Opensearch and then we use the @type rewrite_tag_filter to retag our logs and re-emit our logs with a the new tag.
By doing so, we’re are basically looking for specific logs by executing a regex on the log field of the log stream and if we get a match then we tag it with splunk.myapp . In this way we can then match the logs with that tag with another match section, in our case Splunk by using the fluent-plugin-splunk-hec plugin.
Dockerfile
To achive the above we need multiple Fluentd plugins so let’s craft our Dockerfile. At the time of writing, the latest Fluentd version is 1.15.2
FROM fluent/Fluentd:v1.15.2-debian-1.0
# Use root account to use apt
USER root
RUN buildDeps="sudo make gcc g++ libc-dev" \
&& apt-get update \
&& apt-get install -y --no-install-recommends $buildDeps \
&& gem install fluent-plugin-opensearch \
&& gem install fluent-plugin-rewrite-tag-filter \
&& gem install fluent-plugin-splunk-hec \
&& sudo gem sources --clear-all \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
RUN mkdir -p /var/log/fluentd-buffers/ && chown -R fluent /var/log/fluentd-buffers/
USER fluent
Then build and push this Docker image.
So far so good, let’s deploy Fluentd with our new image.
kubectl apply -f fluentd-sts.yaml
And whoops!
~ ❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
fluentd-0 1/2 CrashLoopBackOff 2 (26s ago) 54s
Debugging our Gems
Let’s see what’s going on by checking the logs:
2022-10-22 16:27:22 +0000 [info]: parsing config file is succeeded path="/fluentd/etc/fluent.conf"
2022-10-22 16:27:22 +0000 [info]: gem 'fluentd' version '1.15.2'
2022-10-22 16:27:22 +0000 [info]: gem 'fluent-plugin-opensearch' version '1.0.8'
2022-10-22 16:27:22 +0000 [info]: gem 'fluent-plugin-rewrite-tag-filter' version '2.4.0'
2022-10-22 16:27:22 +0000 [info]: gem 'fluent-plugin-splunk-hec' version '1.3.0'
/usr/local/lib/ruby/3.1.0/rubygems/specification.rb:2236:in `raise_if_conflicts': Unable to activate fluent-plugin-opensearch-1.0.8, because faraday-2.6.0 conflicts with faraday (~> 1.10) (Gem::ConflictError)
from /usr/local/lib/ruby/3.1.0/rubygems/specification.rb:1367:in `activate'
from /usr/local/lib/ruby/3.1.0/rubygems.rb:211:in `rescue in try_activate'
from /usr/local/lib/ruby/3.1.0/rubygems.rb:204:in `try_activate'
<OMITTED STACKTRACE>
But it was working before installing the fluent-plugin-splunk-hec! This plugin must have introduced a dependency which now conflicts with other gems: Unable to activate fluent-plugin-opensearch-1.0.8, because faraday-2.6.0 conflicts with faraday (~> 1.10) (Gem::ConflictError). This error messages says that the Opensearch plugin cannot be activated since it requires faraday version 1.x but Fluentd has loaded faraday-2.6.0 since it was required by another plugin. But which plugin? We can try to debug this issue by exec(ing) inside the Fluentd pod by performing a trick to avoid restarts of the pod:
<omitted>
containers:
- name: fluentd
image: our-registry.com/fluentd:broken-version
command: ["/bin/sh", "-ec", "while :; do echo '.'; sleep 100000000 ; done"]
<omitted>
then exec
kubectl exec -it fluentd-0 -c fluentd
fluent@fluentd-0:/$ gem list | grep faraday
faraday (2.6.0, 1.10.2)
faraday-em_http (1.0.0)
faraday-em_synchrony (1.0.0)
faraday-excon (1.1.0)
faraday-follow_redirects (0.3.0)
faraday-httpclient (1.0.1)
faraday-multipart (1.0.4)
faraday-net_http (3.0.1, 1.0.1)
faraday-net_http_persistent (1.2.0)
faraday-patron (1.0.0)
faraday-rack (1.0.0)
faraday-retry (1.0.3)
faraday_middleware-aws-sigv4 (0.6.1)
We can see that we have two versions of faraday, 2.6.0 and 1.10.2 and this is totally fine but Ruby cannot load multiple gems at the same time because their code would conflict! So it loaded the newest one.
Let’s check which gem is using faraday-2.6.0
fluent@fluentd-0:/$ gem dependency faraday -v 2.6.0 --reverse-dependencies
Gem faraday-2.6.0
faraday-net_http (>= 2.0, < 3.1)
ruby2_keywords (>= 0.0.4)
Used by
faraday-follow_redirects-0.3.0 (faraday (>= 1, < 3))
faraday-net_http-3.0.1 (faraday (>= 2.5, development))
json-jwt-1.16.1 (faraday (~> 2.0))
opensearch-transport-2.0.1 (faraday (>= 1.0, < 3))
rack-oauth2-2.2.0 (faraday (~> 2.0))
swd-2.0.2 (faraday (~> 2.0))
webfinger-2.1.2 (faraday (~> 2.0))
How can we solve this dependency issue?
Bundler to the rescue
In Ruby there is bundler which is “an exit from dependency hell, and ensures that the gems you need are present in development, staging, and production […] and provides a consistent environment for Ruby projects by tracking and installing the exact gems and versions that are needed. “. So basically it automatically resolves our dependency issue by installing the dependency which satisfies all the gems dependency requirements! In order to use it, we need to change our Dockerfile like so:
FROM fluent/fluentd:v1.15.2-debian-1.0
# Use root account to use apt
USER root
WORKDIR /home/fluent
ENV PATH /fluentd/vendor/bundle/ruby/3.1.0/bin:$PATH
# override gem_path and gem_home paths since Fluentd looks here for its plugins
ENV GEM_PATH /fluentd/vendor/bundle/ruby/3.1.0
ENV GEM_HOME /fluentd/vendor/bundle/ruby/3.1.0
# skip runtime bundler installation
ENV FLUENTD_DISABLE_BUNDLER_INJECTION 1
COPY Gemfile* /fluentd/
RUN buildDeps="sudo make gcc g++ libc-dev libffi-dev" \
runtimeDeps="" \
&& apt-get update \
&& apt-get upgrade -y \
&& apt-get install \
-y --no-install-recommends \
$buildDeps $runtimeDeps net-tools \
&& gem install bundler --version 2.2.24 \
&& bundle config silence_root_warning true \
&& bundle install --gemfile=/fluentd/Gemfile --path=/fluentd/vendor/bundle \
&& SUDO_FORCE_REMOVE=yes \
apt-get purge -y --auto-remove \
-o APT::AutoRemove::RecommendsImportant=false \
$buildDeps \
&& rm -rf /var/lib/apt/lists/* \
&& gem sources --clear-all \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
RUN mkdir -p /var/log/fluentd-buffers/ && chown -R fluent /var/log/fluentd-buffers/
USER fluent
The crucial part here is the bundler installation and then the gem installation with bundle install--gemfile=/Fluentd/Gemfile --path=/Fluentd/vendor/bundle, which takes a Gemfile as input. But what is a Gemfile? A Gemfile is a Ruby file that defines your ruby dependencies.
source "https://rubygems.org"
gem "fluentd", "1.15.2"
gem "oj", "~> 3.13.0"
gem "rexml", "~> 3.2.5"
gem "fluent-plugin-multi-format-parser", "~> 1.0.0"
gem "fluent-plugin-concat", "~> 2.5.0"
gem "fluent-plugin-grok-parser", "~> 2.6.2"
gem "fluent-plugin-prometheus", "~> 2.0.2"
gem 'fluent-plugin-json-in-json-2', ">= 1.0.2"
gem "fluent-plugin-record-modifier", "~> 2.1.0"
gem "fluent-plugin-detect-exceptions", "~> 0.0.13"
gem "fluent-plugin-rewrite-tag-filter", "~> 2.4.0"
gem "fluent-plugin-parser-cri", "~> 0.1.0"
gem "fluent-plugin-kubernetes_metadata_filter", "~> 2.13.0"
gem "ffi"
gem "fluent-plugin-systemd", "~> 1.0.5"
gem "fluent-plugin-opensearch", "1.0.8"
gem "fluent-plugin-splunk-hec", "1.3.0"
Here we specify all the plugins we want in our Fluentd Docker image.
Let’s Docker build ... and deploy our Fluentd with the new image.
~ ❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
fluentd-0 2/2 Running 0 10s
Great. Let’s exec and see which faraday version bundler sorted for us.
fluent@fluentd-0:~$ gem list | grep faraday
faraday (1.10.2)
faraday-em_http (1.0.0)
faraday-em_synchrony (1.0.0)
faraday-excon (1.1.0)
faraday-httpclient (1.0.1)
faraday-multipart (1.0.4)
faraday-net_http (1.0.1)
faraday-net_http_persistent (1.2.0)
faraday-patron (1.0.0)
faraday-rack (1.0.0)
faraday-retry (1.0.3)
faraday_middleware (1.2.0)
faraday_middleware-aws-sigv4 (0.6.1)
So no more 2.6.0. Bundler sorted out the dependency issue for us and decided that the version 1.10.2 satisifes all the dependency requirements. We can finally send our logs to both Splunk and Opensearch.
Conclusion
Fluentd is now sending logs to multiple destination by using the copy plugin. The initial setup was not suitable anymore (installing gems manually with gem install <gem>) for our use case since we had an incompatibility issue with the Fluentd plugins; in particular, we had that issue since the installation of the splunk-hec Fluentd plugin. We solved that by introducing Bundler, which is a dependency manager for Ruby that automatically sorted out the gem to install that satisfied all the dependency between all the gems!
A part of the final Dockerfile is taken from here. I preferred to not use this Docker image since I want to craft my own Dockerfile and install different plugins on top of the official base image of Fluentd. This is a more flexible solution for my use cases which comes with its own challenges.