This is a series. You can find part 2 here and part 3 here.
Managing multiple Kubernetes clusters is not so easy; even more managing the logs that are produced from these clusters. The architecture that I want to show you is still a WIP but on the right track.
Let’s start from this scenario: 15 Kubernetes clusters (that we will call Tenants) where Spring Boot based microservices are running. We need to provide to the developers a central logging dashboard where they can navigate and correlate logs; in this case we will use OpenSearch (formerly known as Open Distro for ElasticSearch). Why Opensearch and not Elasticsearch? Well, we will talk about it in another post but the idea is to setup an anomaly detector / alerting and LDAP integration that are paid/trial features at the moment. Since we are in a early stage development, OpenSearch seems the right choice for us.
As you may recall from the previous post about how I containerize and deploy Spring Boot based application on Kubernetes it’s on the test environment that we let the application log with the Logback logstash encoder in JSON.
So, what are our choices for the logging architecture? The idea is having on each Kubernetes cluster FluentBit as Daemonset (forwarder) that sends logs to a central FluentD) aggregator.
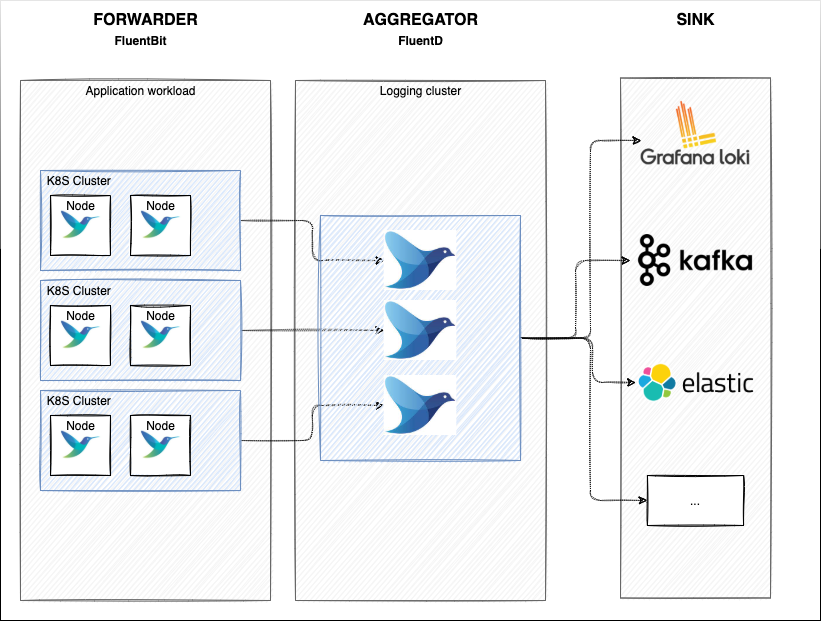
This allows us to have a lightweight log forwarder on the nodes where the actual application workload is performed and then filter/buffer/routing on the FluentD aggregator: having a central FluentD allows us to scale indipendently on the workload and have a central component where we can decide routing(today we’re sending logs just to Opensearch but in the future we can also ship to different destination) instead of logging inside each Kubernetes test cluster and performing the edit.
Overall Architecture
The Idea is to deploy FluentBit on each cluster that forward logs to a central cluster where our FluentD and Opensearch reside: the central logging cluster.
In front of FluentD we will have the Nginx Ingress controller configured to balance to TCP services (FluentD) and then sink in OpenSearch.
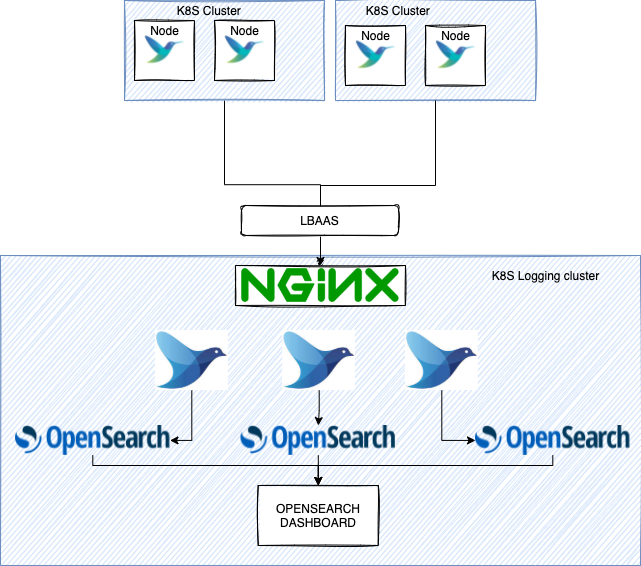
In OpenSearch we will have to define indexes and how to isolate them by tenant ID. This will be the topic for part 2. For now just know that we will create an index for each tenant.
FluentBit Setup
We will deploy a simple FluentBit daemonset on the target clusters and configure it to get Spring boot application logs and forward them with the Forward Protocol to FluentD.
fluentbit-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
labels:
k8s-app: fluent-bit
data:
# Configuration files: server, input, filters and output
# ======================================================
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level debug
Daemon off
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
@INCLUDE input-kubernetes.conf
@INCLUDE filter-kubernetes.conf
@INCLUDE output-forward.conf
input-kubernetes.conf: |
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*_my_namespace_*.log
Exclude_Path /var/log/containers/*i_dont_want_some_logs*.log
Parser cri
DB /var/log/flb_kube-my_namespace.db
Mem_Buf_Limit 60MB
Skip_Long_Lines On
Refresh_Interval 10
filter-kubernetes.conf: |
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.my_namespace.var.log.containers.
Merge_Log On
Use_Kubelet true
Kubelet_Port 10250
Buffer_Size 0
output-forward.conf: |
[OUTPUT]
Name forward
Match *
Host 169.254.168.254 # The Ip that is in front of FluentD. In my case Nginx ingress controller Load Balancer's IP
Port 32000
tls off
tls.verify off
parsers.conf: |
[PARSER]
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<log>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
That’s all for FluentBit. Now it will start to collect logs from the nodes and forward them to the our central logging cluster.
Nginx configuration
So here we will make use of Nginx ingress controller as we do not want to expose FluentD as a NodePort. Since FluentD/Bit communicate through the Forward protocol we need to instruct Nginx to forward TCP traffic the FluentBit traffic to FluentD.
In order to do so we will define the tcp-service configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: tcp-services
namespace: ingress-nginx
data:
32000: "logging/fluentd:32000"
Here basically we’re definining where FluentD resides (logging namespace) and which port has been exposed for it (32000) then make use of this configmap by modifing the Nginx deployment Args
[OMITTED]
containers:
- name: controller
image: k8s.gcr.io/ingress-nginx/controller:v1.0.5@sha256:55a1fcda5b7657c372515fe402c3e39ad93aa59f6e4378e82acd99912fe6028d
imagePullPolicy: IfNotPresent
lifecycle:
preStop:
exec:
command:
- /wait-shutdown
args:
- /nginx-ingress-controller
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services # add this line
- --publish-service=$(POD_NAMESPACE)/ingress-nginx-controller
- --election-id=ingress-controller-leader
- --controller-class=k8s.io/ingress-nginx
- --configmap=$(POD_NAMESPACE)/ingress-nginx-controller
- --validating-webhook=:8443
- --validating-webhook-certificate=/usr/local/certificates/cert
- --validating-webhook-key=/usr/local/certificates/key
- --enable-ssl-passthrough
This is not the last thing we need to perform for Nginx, we also need to expose port 32000. Since in my setup Nginx expose NodePort (and then I manually configure the Load Balancer on my cloud provider), we also need to change the Nginx Service exposed ports
apiVersion: v1
kind: Service
metadata:
annotations:
labels:
helm.sh/chart: ingress-nginx-4.0.7
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 1.0.5
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: controller
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
type: NodePort
externalTrafficPolicy: Local
ports:
- name: http
port: 80
nodePort: 30080
protocol: TCP
targetPort: http
- name: https
port: 443
nodePort: 30443
protocol: TCP
targetPort: https
- name: proxied-tcp-32000 # Add this section
port: 32000
nodePort: 32000
targetPort: 32000
protocol: TCP
- name: metrics
port: 10254
protocol: TCP
targetPort: metrics
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/component: controller
And then edit the LBAAS (the cloud provider load balancer to balance TCP traffic on the K8S node ports on port 32000).
FluentD configuration
Since we’re using OpenSearch we can’t use the latest official FluentD docker images as FluentD will complain about the ES version and this message will be logged:
The client noticed that the server is not a supported distribution of Elasticsearch
So we need to use an older FluentD version. The community is still developing the OpenSearch client library for FluentD but at the time of writing this post the lib has not been released yet.
So we ended up crafting the Docker image like this
FROM fluent/fluentd:v1.13-debian-1
# Use root account to use apt
USER root
# below RUN includes plugin as examples elasticsearch is not required
# you may customize including plugins as you wish
RUN buildDeps="sudo make gcc g++ libc-dev" \
&& apt-get update \
&& apt-get install -y --no-install-recommends $buildDeps \
&& gem install elasticsearch-api -v 7.13.3 \
&& gem install elasticsearch-transport -v 7.13.3 \
&& gem install elasticsearch -v 7.13.3 \
&& gem install fluent-plugin-elasticsearch -v 5.1.0 \
&& sudo gem sources --clear-all \
&& SUDO_FORCE_REMOVE=yes \
apt-get purge -y --auto-remove \
-o APT::AutoRemove::RecommendsImportant=false \
$buildDeps \
&& rm -rf /var/lib/apt/lists/* \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
RUN mkdir -p /var/log/fluentd-buffers/ && chown -R fluent /var/log/fluentd-buffers/
USER fluent
Once built and pushed, we can write down our FluentD configuration. Since we’re are going to manage a lot of clusters for multiple projects (Tenants) I will split FluentD configmap in multiple configmaps (note: I will share here just the configuration for tenant-1 but basically we need to repeat the configuration for each of it).
main-fluentd-conf.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-es-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
fluent.conf: |-
<source>
type forward
bind 0.0.0.0
port 32000
</source>
<filter kube.**>
@type record_transformer
remove_keys $.kubernetes.annotations, $.kubernetes.labels, $.kubernetes.pod_id, $.kubernetes.docker_id, logtag
</filter>
<filter kube.tenant-1.**>
@type record_transformer
<record>
tenant_id "tenant-1"
</record>
</filter>
<filter kube.tenant-2.**>
@type record_transformer
<record>
tenant_id "tenant-2"
</record>
</filter>
<filter kube.tenant-3.**>
@type record_transformer
<record>
tenant_id "tenant-3"
</record>
</filter>
@include /fluentd/etc/prometheus.conf
@include /fluentd/etc/tenant-1.conf
@include /fluentd/etc/tenant-2.conf
@include /fluentd/etc/tenant-3.conf
[...]
As you can see in the main fluentD configmap we are defining we want to use the forward protocol on port 3200 (where we expect FluentBit logs) and define a couple of filters: we remove some unnecessary fields such as deployment annotations/labels (usually the developers that are going to consume these logs are not making use of these fields. They just need the content of the logs plus some basic information such as pod name, namespace etc.).
Then for each tenant we add a custom field to each log: the Tenant ID. In this way we can achieve some advanced filtering/routing in OpenSearch (that we will see in Part 2 of this post).
At the very end we include the other confs, in order of functionality. As you may note there is the prometheus.conf : with this configuration we will let FluentD to expose interesting metrics such as number of logs flowing in/out and much more.
prometheus-conf.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-prometheus-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
prometheus.conf: |-
<source>
@type prometheus
bind "#{ENV['FLUENTD_PROMETHEUS_BIND'] || '0.0.0.0'}"
port "#{ENV['FLUENTD_PROMETHEUS_PORT'] || '24231'}"
metrics_path "#{ENV['FLUENTD_PROMETHEUS_PATH'] || '/metrics'}"
</source>
<source>
@type prometheus_output_monitor
interval 10
</source>
<filter kube.**>
@type prometheus
<metric>
name fluentd_input_status_num_records_total
type counter
desc The total number of incoming records
<labels>
tenant_id ${tenant_id}
</labels>
</metric>
</filter>
We would also like to know which tenant is sending logs so we add the label tenant_id
tenant-1-conf.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-tenant-1-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
tenant-1.conf: |-
<match kube.tenant-1.**>
@type elasticsearch
@id out_es_tenant-1
@log_level "info"
id_key _hash
remove_keys _hash
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST'] || 'localhost'}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT'] || '9200'}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER'] || 'admin'}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD'] || 'admin'}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify false
reload_connections false
reconnect_on_error true
reload_on_failure true
logstash_prefix "tenant-1-my-namespace"
logstash_dateformat "%Y.%m.%d"
logstash_format true
type_name "_doc"
suppress_type_name true
template_overwrite true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/tenant-1/my-namespace/kubernetes.system.buffer
retry_type exponential_backoff
flush_thread_count 2
flush_interval 10s
retry_max_interval 30
retry_forever true
chunk_limit_size 8M
queue_limit_length 512
overflow_action block
</buffer>
</match>
Then the configuration related to the tenant-1: we use the elasticsearch @type plugin here to sink logs to OpenSearch.
At the end you just need to configure indexes in OpenSearch. You will find your logs there!
Conclusion
In this post we saw how to create a Logging infrastructure by using FluentBit, FluentD, OpenSearch and Kubernetes. By leveraging the Forwarder/Aggregator model we can have a central logging cluster where configure filters/buffer/routing for all the logs coming from our clusters. In this scenario the source clusters are tenants (indipendent projects) that send logs to a central OpenSearch cluster where they can explore, aggregate them. Keep in mind that with this configuration we ended up with 1 index = 1 tenant, something that we need to keep in mind if in the future we plan to manage >10/100 tenants. In the next part we will focus on OpenSearch and how to achive a better scaling by having one single shared index without letting the tenant know about it, still maintaining segregation.