Here are some notes about how I run a Spring Boot application on Kubernetes. This is the 2nd part of a series of articles about Spring Boot applications on Kubernetes. You can find the 1st part here.
Running a JVM based application on Kubernetes seems a pretty easy task but there are a lot of things to take in consideration:
- Application containerization
- Startup
- Graceful shutdown
- JVM & Resource limits
Application containerization
In order to containerize a Spring Boot application I leverage the (not so) new layering feature: this allows to create a Docker Layer for each part of our application:
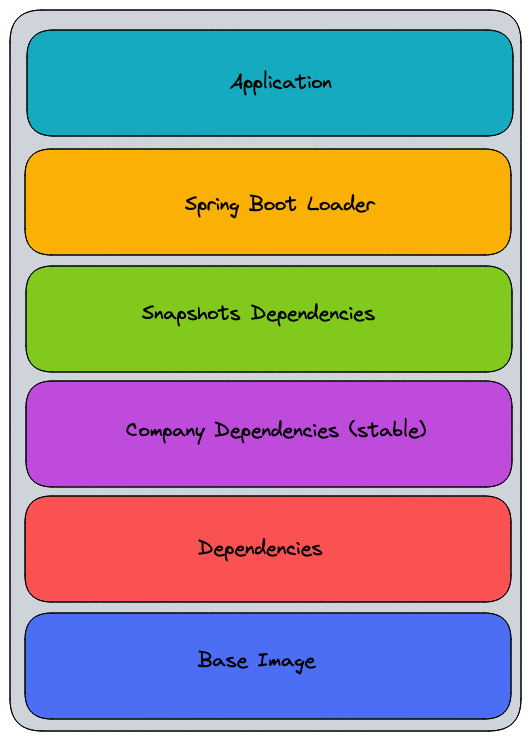
Docker Layers allow us to separate our dependencies and application files into different layers hence these can be be reused (when it’s possible). This will lead to reduced size for our docker images.
In order to do so we have to create a layers.xml file in our project like so:
<layers xmlns="http://www.springframework.org/schema/boot/layers"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/boot/layers
https://www.springframework.org/schema/boot/layers/layers-{spring-boot-xsd-version}.xsd">
<application>
<into layer="spring-boot-loader">
<include>org/springframework/boot/loader/**</include>
</into>
<into layer="application" />
</application>
<dependencies>
<into layer="snapshot-dependencies">
<include>*:*:*SNAPSHOT</include>
</into>
<into layer="company-dependencies">
<include>it.mycompany.*:*</include>
</into>
<into layer="dependencies"/>
</dependencies>
<layerOrder>
<layer>dependencies</layer>
<layer>spring-boot-loader</layer>
<layer>snapshot-dependencies</layer>
<layer>company-dependencies</layer>
<layer>application</layer>
</layerOrder>
</layers>
where we specify what are the layers we want to create from our application.
In order to use make use of the layered jar, we need to modify the spring-boot-maven-plugin inside the pom.xml
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<layers>
<enabled>true</enabled>
<configuration>${project.basedir}/src/layers.xml</configuration> <!-- I put the layers.xml file inside src -->
</layers>
</configuration>
</plugin>
Then we can write our Dockerfile in the following way
ARG BUILD_IMAGE=my-registry/base-image/maven-adoptopenjdk-11:release-3.6
ARG RUNTIME_IMAGE=my-registry/base-image/distroless-java:release-11
FROM ${BUILD_IMAGE} as builder
WORKDIR /output
COPY pom.xml .
RUN mvn -Dmaven.repo.local=/image-cache/repository -s /maven-settings/settings.xml -e dependency:resolve
COPY src /output/src
RUN mvn -U -Dmaven.repo.local=/image-cache/repository -s /maven-settings/settings.xml clean package -Djib.skip=true
RUN java -Djarmode=layertools -jar /output/target/app.jar extract
FROM builder AS test
RUN mvn sonar:sonar -Dmaven.repo.local=/image-cache/repository -s /maven-settings/settings.xml
FROM ${RUNTIME_IMAGE} as production
WORKDIR /application
COPY --from=builder /output/dependencies/ ./
COPY --from=builder /output/company-dependencies/ ./
COPY --from=builder /output/snapshot-dependencies/ ./
COPY --from=builder /output/spring-boot-loader/ ./
COPY --from=builder /output/application/ ./
ENTRYPOINT ["java","-Dfile.encoding=UTF-8","-Dspring.config.additional-location=/config/","-agentlib:jdwp=server=y,transport=dt_socket,address=9000,suspend=n","org.springframework.boot.loader.JarLauncher"]
Let’s break it up: as you can see the whole build is performed in this multi stage Dockerfile.
- first stage: here I perform the build by leveraging a volume cache I use to speed up the builds, then the last run is the command that enables us to produce the layerd jars.
- second stage (optional): after the build I perform a sonar quality code check
- third stage: here I define the various layers that will be contained inside the final Docker image. The Entrypoint makes use of the “org.springframework.boot.loader.JarLauncher” since we don’t have a jar file to launch.
Then you just execute docker build --target production
NOTE: starting from Spring Boot 2.4 layering is enabled by default.
Startup
By default I include liveness & readiness probes as checks to perform by Kubernetes in order to make sure that our application is working well:
-
liveness endpoint: it’s probed by Kubernetes in order to check if the application is still working properly and if it returns a status code != 2xx then Kubernetes will restart the pod if the failureThreshold condition is met. Spring Boot implements the LivenessState Enum with two values to encapsulate the state of the application:
- CORRECT: means the application is working properly and the internal state is correct
- BROKEN: the application is experiencing fatal failures
-
readiness endpoint: it’s probed by Kubernetes in order to check if the application is ready to serve requests; if Kubernetes receives a status code != 2xx for the number configured in the failureThreshold then it will put the pod in not ready status so new requests are not going to be forwarded anymore until a positive status code is received. Spring Boot implements the ReadinessState enum with two values to encapsulate the state of the application:
- ACCEPTING_TRAFFIC: the application is OK and ready to accept any traffic
- REFUSING_TRAFFIC: the application is not OK and cannot accept requests
livenessProbe:
failureThreshold: 5
httpGet:
path: /actuator/liveness
port: 8080
periodSeconds: 10
timeoutSeconds: 3
initialDelaySeconds: 30
readinessProbe:
failureThreshold: 3
httpGet:
path: /actuator/readiness
port: 8080
initialDelaySeconds: 50
periodSeconds: 10
timeoutSeconds: 3
Keep in mind that these endpoints return the overall health of the application so if it cannot connect to a remote service (ex. Database) it doesn’t make to restart the application over and over until the remote service is up and running again.
Starting from Kubernetes 2.2 Spring introduced health groups that allow to group liveness and readiness indicators under the health group that can be enabled by putting:
management.endpoint.health.probes.enabled=true
So now we have these endpoints:
- /actuator/health/liveness
- /actuator/health/readiness
and by default these indicators won’t check any external state! but check only for the internal application state.
If you still want to check for external connectivity (for example you want to check the application has connectivity to MongoDB), you can customize the behaviour by setting:
management.endpoint.health.group.liveness.include=livenessState,mongo
management.endpoint.health.group.readiness.include=readinessState,mongo
You can find a list of indicators that you can use here
You can also write custom health indicator by implementing the HealthIndicator interface:
@Component
public class DummyHealthIndicator implements HealthIndicator {
@Override
public Health health() {
Health.Builder status = Health.up();
return status.build();
}
}
and then include it in our readiness endpoint:
management.endpoint.health.group.readiness.include=readinessState,dummy
For security reasons is better to move the actuator endpoints to a different management port since we can expose sensitive information/endpoints:
management.server.port=9000
but this change will lead the indicators to use a different web infrastructure as the main application thus the indicators will return a positive status code even that the main appliction is not working properly.
In order to avoid this, starting from Spring boot 2.6, we can expose endpoints published on the management port to the server port:
management.endpoint.health.group.readiness.additional-path="server:/health/readiness"
management.endpoint.health.group.liveness.additional-path="server:/health/liveness"
So at the end we gonna end up with:
livenessProbe:
failureThreshold: 5
httpGet:
path: /health/liveness
port: 8080
periodSeconds: 10
timeoutSeconds: 3
initialDelaySeconds: 30
readinessProbe:
failureThreshold: 3
httpGet:
path: /health/readiness
port: 8080
initialDelaySeconds: 50
periodSeconds: 10
timeoutSeconds: 3
Graceful shutdown
We want to make sure that our application can handle shut downs in a graceful way so it can still process requests while shutting down, otherwise clients will receive a bad status code.
In Spring Boot we can achieve the above by settings two properties:
server.shutdown=graceful
spring.lifecycle.timeout-per-shutdown-phase=20s
The first property enables graceful shutdowns when the application receives the SIGTERM command and the second property specifies how many seconds to wait before killing the pending requests.
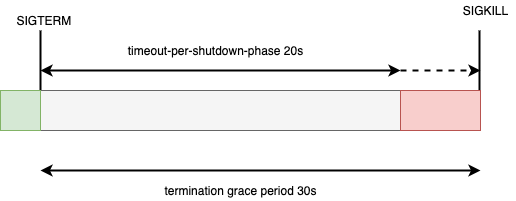
It’s important to set spring.lifecycle.timeout-per-shutdown-phase less than the terminationGracePeriodSeconds from the deployment/statefulset (by default 30s) because as soon the value associated with this setting is reached, the application will be killed and our graceful shutdown won’t work. So: spring.lifecycle.timeout-per-shutdown-phase < terminationGracePeriodSeconds
JVM & Resource Limits
CPU
Kubernetes has two parameters to manage CPU resource: limits and requests
resources:
limits:
cpu: 1500m
memory: 3Gi
requests:
cpu: 500m
memory: 1Gi
Let’s start by saying that,regarding the CPU, spec.containers[].resources.requests.cpu are the CPU shares and spec.containers[].resources.limits.cpu is the CPU quota.
In order to calculate the number of CPUs, the JVM, calls the Runtime.getRuntime().availableProcessors() that returns the number of CPUs of the VM or the value set as CPU Quota (starting from Java 11 the -XX:+PreferContainerQuotaForCPUCount is by default true. For Java <= 10 the CPU count is equal to the CPU shares) in order to calculate how many compiler threads, GC threads, and sizing of the fork-join pool.
Usually I don’t set CPU quota in order to utilize Kubernetes resources as much as possible and leverage the cpu shares to guarantee to each container their time share.
Now there is an issue, not related to CPU limits but is a side-effect of the choice above: imagine the following scenario where you deploy 2 application, one after one on a node that has 32 Cores.
The first container requests 8 cores out of the 32 available but since the node is empty it gets alle the 32 cores. The second container requests 2 cores out of the 32 cores (requested cores are 10), then each container gets 16 cores each.
As you can see the value returned from Runtime.getRuntime().availableProcessors() changes over time!
So the best solution here is to set -XX:ActiveProcessorCount=X manually where X is the number of cores you want to show to the JVM.
If you need to set CPU limits
If you need to set CPU Limits then keep in mind the following:
let’s say we have an application (single threaded) that takes 500ms to perform a job without cpu limits.
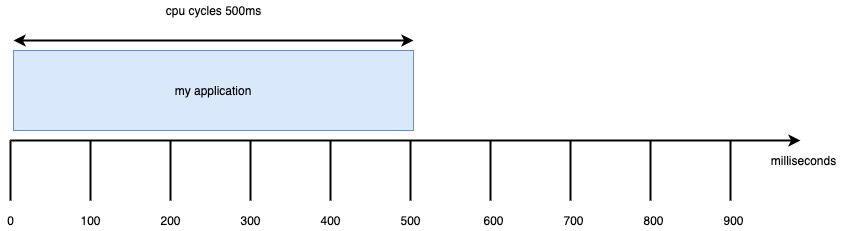
and we introduce cpu limits equal to 550millicore (cfs_quota_us = 550m = 55,000us = 55ms)

Update 14/07/23: I noticed that I made a mistake with the image above. The “work” and “throttled” blocks must be inside the 100ms slots. So the application runs for 55ms then it is throttled for 45ms (55 + 45 = 100ms , the cfs_period).
then the application will take 1400ms to complete since it will be throttled every 55ms (quota depletetion) and will need to wait 100ms 45ms for each cycle (cfs_period).
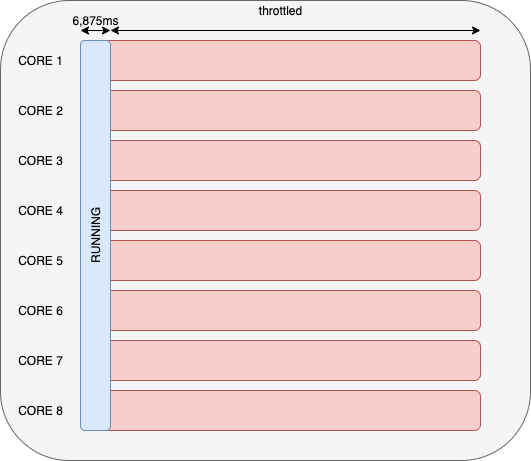
For multi-threaded applications, if you run on a 8 core VM then the quota will be depleted in 6,875ms!
Memory
Regarding the memory, I usually set limits=requests and customize the java heap size by setting -XX:MaxRAMPercentage=50; in fact by default the available heap memory reserved to the application will be 25% of the total amount of memory… by setting the parameter above we’re specifying we want half of the available memory for the heap and the other 50% for the off-heap.
You can specify these flags by using the JAVA_TOOL_OPTIONS environment variable.
NB: Do your tests/load testing first then modify the JVM parameters / CPU limits and requests accordingly! Do not take for granted that your application will work fine just by setting those parameters.