With the consistent increasing of projects we were experiencing a huge growth of Kubernetes clusters for dev and test environments; each project had its own cluster with its stack: Nginx, Prometheus, Opa Gatekeeper etc. Moreover, each cluster had a different Kubernetes version with legacy clusters still pinned to the 1.15.x version. This meant we had to manage a different set of stacks (Prometheus, Nginx etc) since the skew between versions were too big. For example if you try to deploy the latest Prometheus stack on a Kubernetes 1.15.x you will notice that won’t work (also by having a look at the compatibility matrix link you would have known that :) ).
So we were in a situation with an incredible amount of technological overhead, low cluster resource efficiency and high complexity given by the number of clusters.
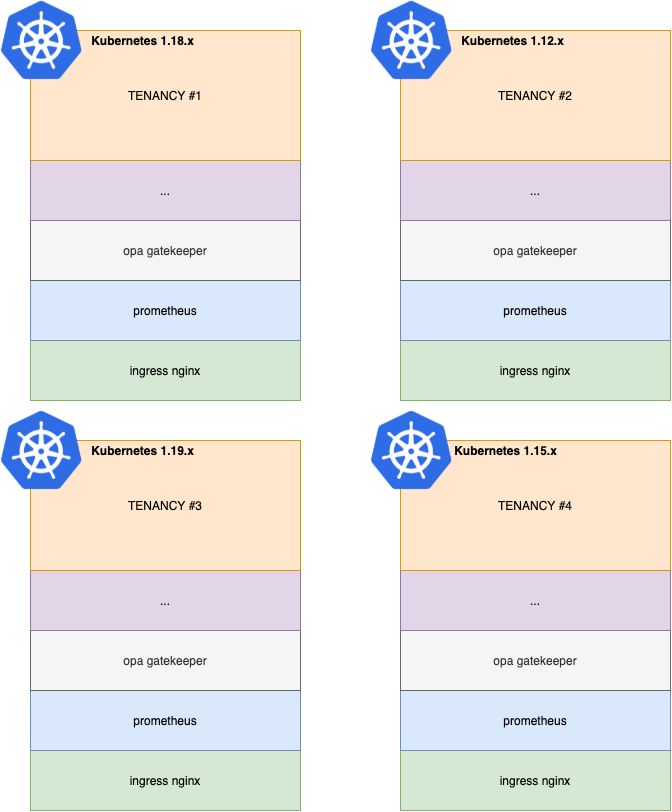
Our ideal scenario would have been a single multitenant (hence multiple projects) cluster for the dev environment and another one for the test cluster. This would have allowed us to reduce the burden of managing like > 30 clusters to just two and keeping just one stack for Prometheus, Nginx etc. since we would have managed only one Kubernetes version.
So the natural solution would be a single cluster with multiple namespaces. But then as I already told you, we need to manage different Kubernetes versions, since in production each project is running on a different cluster with a different version.
Introducing Vcluster
Vcluster is a solution that allows us to run Virtual Kubernetes clusters inside regular namespaces. It works by having an api server and storage backend deployed as stateful set and then it schedules pods inside the underlying cluster while having a separate control plane. In addition to the api server it also deployes a scheduler which syncs resources between the host cluster and Vcluster. It supports k3s, k0s and “vanilla” k8s distribution where the backend storage depends on the distribution; for example, for k3s we have
- embedded SQLite
- PostgreSQL
- MySQL
- MariaDB
- Etcd
So at this point you already figured out that you can have many Vclusters within a single cluster hence you have less management and less maintenance effort to operate the cluster (vs having multiple clusters).
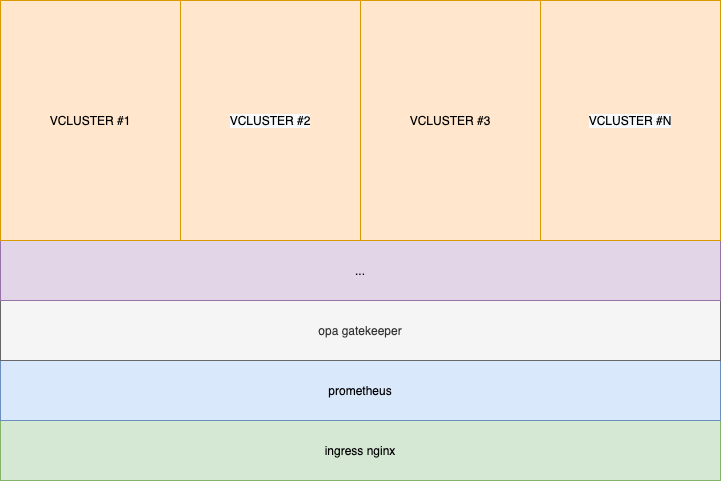
This is our way to go to solve the issue I just described you.
Our Scenario
We want to have a single dev cluster and then create 1 Vcluster for each tenant (project). Let’s start by deploying on our host cluster (which already have installed Nginx ingress controller, OPA Gatekeeper, Calico and Prometheus) our first Vcluster by using Helm:
vcluster:
image: rancher/k3s:v1.23.3-k3s1
command:
- /bin/k3s
extraArgs:
- --service-cidr=10.96.0.0/16 # this is equal to the service CIDR from the host cluster
volumeMounts:
- mountPath: /data
name: data
resources:
limits:
memory: 2Gi
requests:
cpu: 200m
memory: 256Mi
# Storage settings for the vcluster
storage:
# If this is disabled, vcluster will use an emptyDir instead
# of a PersistentVolumeClaim
persistence: true
# Size of the persistent volume claim
size: 50Gi
# Optional StorageClass used for the pvc
# if empty default StorageClass defined in your host cluster will be used
className: oci-bv
sync:
networkpolicies:
enabled: true # we want to sync network policies from the vcluster to the host cluster
priorityclasses:
enabled: false
persistentvolumes:
enabled: true # we want to sync PV from the vcluster to the host cluster
legacy-storageclasses:
enabled: true # we want to share storage classes from the host cluster to the vcluster
storageclasses:
enabled: false # we don't want to sync storageclasses created from the vcluster to the host cluster
fake-persistentvolumes:
enabled: false
nodes:
enabled: false
syncAllNodes: false
syncer:
extraArgs:
- --tls-san=tenant-1-vcluster.justinpolidori.it
- --override-hosts-container-image=our-registry.sh/alpine:3.13.1 # in order to avoid dockerhub rate limit issues we will instruct Vcluster to use our alpine image for its own activities
And then issue
helm upgrade --install tenant-1 vcluster --values vcluster.yaml --repo https://charts.loft.sh --namespace tenant-1 --repository-config=''
Release "tenant-1" does not exist. Installing it now.
NAME: tenant-1
LAST DEPLOYED: Sun Apr 24 21:30:56 2022
NAMESPACE: tenant-1
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Thank you for installing vcluster.
Your release is named tenant-1.
To learn more about the release, try:
$ helm status tenant-1
$ helm get all tenant-1
With the command above, we provisioned our first Vcluster which will run k3s version 1.23.3 and also we specified which resources to sync between the vcluster and the host cluster; by default, not all resources are synced and since we want to monitor certain resouces from the host cluster with Prometheus, (such as PV, Network Policies etc.) we’re explicitly enabling them. Moreover, by syncing ingresses (by default true) we will enable ourselves to use one shared ingress controller in the host cluster instead of running one ingress controller for each Vcluster.
Connecting to the Vcluster
Once deployed we want to connect to that Vcluster and start to issue commands in it; we have different options to access the cluster which you can find here and if you noticed, we already specified which hostname our api address will respond on: tenant-1-vcluster.justinpolidori.it.
My way to access the cluster is by manually creating a Load Balancer in my cloud provider and then from there point to the nodes where Nginx is exposing NodePorts (yours can be totally different. I have a limitation in place which prevents me to expose Nginx in a different way). Then we expose our Vcluster Api server by using an ingress without SSL-Passthrough, which will be deployed inside the namespace created by the command above (tenant-1) and then access the cluster by using a Service Account.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
#nginx.ingress.kubernetes.io/ssl-passthrough: "true"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
name: tenant-1-vcluster-ingress
namespace: tenant-1
spec:
ingressClassName: nginx
rules:
- host: tenant-1-vcluster.justinpolidori.it
http:
paths:
- backend:
service:
name: tenant-1
port:
number: 443
path: /
pathType: ImplementationSpecific
tls:
- hosts:
- tenant-1-vcluster.justinpolidori.it
Then generate a Kubeconfig for the admin user by issuing the following command which will go through our Ingress
vcluster connect tenant-1 -n tenant-1 --server=https://tenant-1-vcluster.justinpolidori.it --service-account admin --cluster-role cluster-admin --insecure
Then by using that Kubeconfig we can check if we can properly connect and list pods inside the cluster:
kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-86d5cb86f5-stn9q 1/1 Running 0 5m
Resource Quotas + Vcluster
At this point our cluster is fully functional. We can start to create resources in it: we can create ingresses to expose the services, deployments, connect ArgoCD etc. Since our cluster will have multiple Vclusters hence will be shared by multiple tenants, it’s very important to define resources for each tenant. We can achive this by using plain ResourceQuota (and Limit ranges) ! Since each Vcluster is a tenant, resource quotas are our way to go to define quotas without having to deal with any other fancy solution.
Apply the following resources in the host cluster
apiVersion: v1
kind: ResourceQuota
metadata:
name: tenant-1-vcluster-quota
namespace: tenant-1
spec:
hard:
cpu: "20"
memory: 64Gi
pods: "20"
---
apiVersion: v1
kind: LimitRange
metadata:
name: tenant-1-vcluster-limit-range
namespace: tenant-1
spec:
limits:
- default:
memory: 2Gi
cpu: "1"
defaultRequest:
memory: 256Mi
cpu: 200m
type: Container
Now if we try to run a pod which exceeds the quota defined we will get an error. Let’s try to run an Nginx pod with requests above our quota:
kubectl apply -f nginx-pod-with-insane-requests.yaml -n default # in the Vcluster
Warning SyncError 4s (x2 over 24s) pod-syncer Error syncing to physical cluster: Pod "nginx-x-default-x-tenant-1" is invalid: [spec.containers[0].resources.requests: Invalid value: "65000Mi": must be less than or equal to memory limit, spec.containers[0].resources.requests: Invalid value: "21": must be less than or equal to cpu limit]
By the way did you noticed the pod’s name? Let’s check what’s happening from the host cluster’s perspective. On the host cluster list all the pods inside the Vcluster’s namespace:
kubectl get pods -n tenant-1
NAME READY STATUS RESTARTS AGE
nginx-x-default-x-tenant-1 0/1 Pending 0 1h
coredns-86d5cb86f5-stn9q-x-kube-system-x-tenant-1 1/1 Running 0 1h
tenant-1-0 2/2 Running 0 1h
Each deployment/pod/service and in general resouce we’re creating is (as we said at the beginning) being synced on the host cluster and, to avoid any conflict with any other resource, Vcluster is appending a placeholder to the pod name (in our case x), the vcluster’s namespace in which the resource has been created (in case of nginx is default), another placeholder and then the tenant name.
OPA Gatekeeper + Vcluster
Since every resource will be placed in a namespace we can achieve more control by defining policies with OPA Gatekeeper on the host cluster. Let’s say that as cluster’s admin we want to deny the creation of services with NodePort for our tenants. We can achive that by defining the following resources:
apiVersion: config.gatekeeper.sh/v1alpha1
kind: Config
metadata:
name: config
namespace: "gatekeeper-system"
spec:
match:
- excludedNamespaces: ["kube-*","ingress-nginx"] # Skip system namespace and nginx namespace
processes: ["*"]
---
apiVersion: templates.gatekeeper.sh/v1
kind: ConstraintTemplate
metadata:
name: k8sblocknodeport
annotations:
description: >-
Disallows all Services with type NodePort.
https://kubernetes.io/docs/concepts/services-networking/service/#nodeport
spec:
crd:
spec:
names:
kind: K8sBlockNodePort
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8sblocknodeport
violation[{"msg": msg}] {
input.review.kind.kind == "Service"
input.review.object.spec.type == "NodePort"
msg := "User is not allowed to create service of type NodePort"
}
---
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sBlockNodePort
metadata:
name: block-node-port
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Service"]
and apply. Then if we try to deploy a service with a NodePort in the Vcluster we get:
kubectl apply -f disallowed-service-with-node-port.yaml
Error from server ([block-node-port] User is not allowed to create service of type NodePort): error when creating "disallowed-service-with-node-port": admission webhook "validation.gatekeeper.sh" denied the request: [block-node-port] User is not allowed to create service of type NodePort
In conclusion
We started from having dozen of clusters for each tenant to 1 single multitenant cluster by leveraging virtual cluster and, as cluster’s admin, we are very happy with the solution achieved as we don’t have to maintain different stacks for each Kubernetes cluster/version and we can make a better utilization of our resources. I can continue to make examples on how Vclusters lower management and maintenance efforts: we can use Prometheus to monitor all the pods scheduled inside Vcluster from the host cluster, a single fleet of Fluentbit as daemonset deployed on the host cluster to get out logs etc.
Keep in mind that Vcluster guarantees control-plane isolation and dns isolation but doesn’t provide any workload or network isolation: a user from a specific tenant can create pods which can mount host paths, run as root etc. You can have a better control of what is being scheduled by leveraging Gatekeeper and network policies with Calico (or any other CNI which supports them).
In the next post I will show you how to give developers proper access to the vcluster: LDAP authentication/sso to the vcluster’s api server + RBAC .